
How to Build Resilient API Integrations
Use strict timeouts, retry only transient errors with exponential backoff and jitter, employ idempotency, circuit breakers, and clear fallbacks.

Most API failures don’t come from one big outage. They come from slow calls, bad retries, and weak fallback rules.
If I had to boil this down, I’d say this: set hard time limits, retry only the right errors, use jitter, keep non-idempotent writes from duplicating, and plan what the user sees when a dependency is down. That matters because even strong-looking uptime falls apart in a chain. For example, 10 APIs at 99.9% uptime drop to about 99.0% combined reliability, and 30 dependencies at 99.99% each still land near 99.7% composite uptime.
Before I build any integration, I’d make these calls first:
- Rank dependencies by business impact
- Set latency and reliability targets
- Normalize provider errors into one internal format
- Choose sync only where the user needs an immediate answer
- Set connection, read, and total request deadlines
- Retry only transient errors like 429, 502, 503, 504, and 408
- Use exponential backoff with jitter
- Avoid auto-retrying non-idempotent writes unless idempotency keys exist
- Add circuit breakers and clear fallback rules
- Track p95/p99 latency, retry rate, and breaker state changes
- Run failure injection and load tests on a schedule
The main idea is simple: I’m not trying to stop every failure. I’m trying to make failure limited, visible, and safe for users.
Plan for failure before writing integration code
Every dependency fails at some point. So don’t design for perfect uptime. Design for controlled failure.
Before you write any code, map your highest-impact workflows and rank each external dependency by business criticality and acceptable degradation. A payment API outage is not in the same league as a recommendations service outage. What matters most is user impact.
Security-sensitive operations like authentication should fail closed. Lower-priority features like personalization or search enrichment can fail open and fall back to generic content. That split matters more than people think. A system with 30 dependencies, each at 99.99% uptime, still has a composite uptime of only about 99.7% - roughly 2 hours of downtime per month - unless each integration is defended on its own. That ranking shows where strict timeouts, retries, and fallback logic deserve the most attention.
Set reliability and latency targets
Set SLO-style targets for each integration before you pick a timeout.
Define the required outcome, timing, and acceptable staleness for the workflow. For example, how fast does a paid invoice need to show up in accounting? That answer gives you a clear basis for timeout values, retry budgets, and error-budget decisions.
Without those targets, timeout values are just guesses, and retry logic turns into hand-waving. Once the targets are in place, normalize provider failures into one internal error shape.
Standardize the error model and response schema
External APIs fail in all sorts of ways. If those differences leak into application logic, the code gets brittle fast.
Map provider-specific errors into one internal model as soon as they enter your system. Keep the payload consistent with:
- an HTTP status code
- a machine-readable error code
- a human-readable message
- a correlation ID for tracing
RFC 7807 Problem Details is a practical standard for this. Treat 5xx, 408, and 429 responses as retriable. Treat 4xx errors as permanent unless your API says otherwise.
Once failures are normalized, you can make a clean call: should the integration block the request, or should the work continue in the background?
Choose sync or async processing based on failure tolerance
Not every integration belongs in the request path.
Use synchronous calls when the workflow needs an immediate decision and the user feels the failure right away, such as login, inventory checks, or quote eligibility. Use asynchronous processing for state changes and follow-on work like invoice creation, lead enrichment, or subscription renewals.
Async patterns decouple your system from downstream availability. If something breaks, you can retry it on its own or route it to a dead-letter queue for later inspection instead of making the user wait.
And this isn’t just architecture talk. Dependency chains stack failure. If you rely on 10 third-party APIs with 99.9% uptime, combined reliability drops to 99.0%, or about 87 hours of potential downtime per year. Those choices shape the timeout, retry, and fallback rules that come next.
sbb-itb-124fdbf
Implement timeouts and retries without amplifying failures
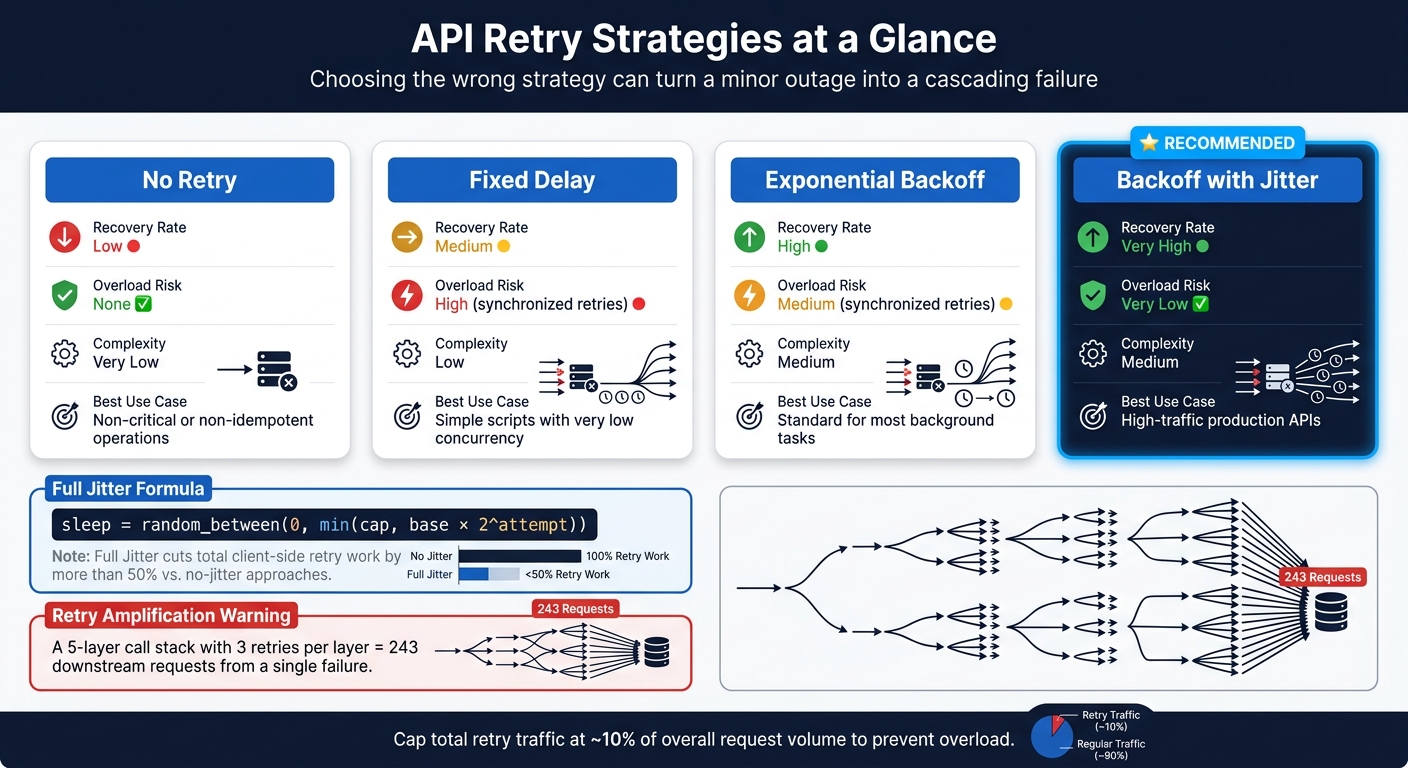
API Retry Strategies Compared: Recovery Rate, Overload Risk & Best Use Cases
Once you know the failure modes, turn them into clear timeout and retry rules.
Timeouts and retries help with short-lived failures. But if you tune them badly, they can make an outage worse. The goal isn't to recover at any cost. It's to keep failure bounded.
AWS DynamoDB's 2015 outage is a good example. A brief network disruption led storage servers to re-request membership data from a metadata service at the same time. That drove error rates to 55% and kept them there for nearly 5 hours.
Here’s how the main retry strategies stack up:
| Strategy | Recovery Rate | Overload Risk | Complexity | Best Use Case |
|---|---|---|---|---|
| No Retry | Low | None | Very Low | Non-critical or non-idempotent operations |
| Fixed Delay | Medium | High (synchronized retries) | Low | Simple scripts with very low concurrency |
| Exponential Backoff | High | Medium (synchronized retries) | Medium | Standard for most background tasks |
| Backoff with Jitter | Very High | Very Low | Medium | High-traffic production APIs |
Use backoff with jitter by default.
Set explicit connection, read, and total request timeouts
Set hard deadlines before you adjust retry counts.
Every integration needs three explicit timeout values. If a dependency stalls, it can tie up workers and slow users down. So set each limit from observed latency, not guesswork:
- The connection timeout limits how long you wait to finish a TCP/TLS handshake. Keep it between 1 and 3 seconds.
- The read timeout limits how long one read call can block on an open socket.
- The overall time limit is the budget for the full operation, including all retry attempts.
If an API usually responds in 200 ms, a timeout between 500 ms and 1 second is a solid starting point. For user-facing calls, keep the total budget within what a user will tolerate. For background jobs, 30 to 60 seconds is a reasonable upper range, but you still need a hard ceiling.
In multi-hop systems, set one end-to-end deadline at the edge and pass it downstream. That way, no service wastes time calling another service when the budget is already gone.
Use exponential backoff and jitter for safe retries
Retry transient errors: 429, 503, 504, 408, 502. Do not retry 400, 401, 403, 404, or 422.
Exponential backoff increases the wait between attempts. Jitter adds randomness so clients don't all retry in lockstep under load. The recommended Full Jitter formula is sleep = random_between(0, min(cap, base * 2^attempt)). Compared with approaches that skip jitter, Full Jitter can cut total client-side retry work by more than half.
Use a retry budget instead of a fixed per-request limit. Cap total retry traffic at about 10% of overall request volume. That keeps retry load more stable when the system is under pressure.
Avoid automatic retries for non-idempotent operations
Do not retry non-idempotent operations unless the API supports idempotency keys.
When the API supports them, use idempotency keys: a UUID sent in a header such as Idempotency-Key: <uuid>. This helps prevent duplicate side effects. If the API does not support idempotency keys, treat the operation as non-retryable.
For service-to-service calls, retry in one layer only, usually the outermost layer, to avoid retry amplification. Otherwise, things can spiral fast. A 5-deep stack with 3 retries at each layer can turn one request into 243 downstream requests.
When retries still fail, fall back or stop the request path.
Add fallbacks, circuit breakers, and graceful degradation
Retries are great for short hiccups. But when a dependency stays sick, more retries just make a bad situation worse.
That’s when resilience shifts gears. Instead of hammering the same failing service, you stop the cascade, return the safest useful result you can, and make sure your team can see what’s going on.
When retries stop helping, isolate the dependency and serve the best safe result.
Use circuit breakers to stop cascading failures
A circuit breaker sits in front of a dependency and watches how calls behave. It has three states: Closed (traffic flows as normal), Open (requests fail right away without touching the dependency), and Half-Open (a small probe checks whether the service has come back).
Here are the four settings that matter most:
- Failure threshold: Trip the circuit at a 50% failure rate or after 5–10 consecutive errors
- Open duration: Wait 30 to 120 seconds before moving to half-open
- Probe behavior: Allow only one test request in half-open. If you let many requests through at once, you can slam a recovering service and knock it right back down. Also, alert on every state change
- Rolling window: Measure failure rate over a 60 to 120 second window
Once the dependency is cut off, pick the lightest fallback that still keeps the workflow moving.
Define fallback behavior for critical and non-critical data
Use the dependency priority you set earlier to decide what must be fresh and what can degrade. Core data should come back first. Optional data should be allowed to fail on its own. That way, one missing extra doesn’t block the entire response.
The right fallback depends on the data itself and how old it can safely be:
| Strategy | Data Freshness | Implementation Effort | User Impact | Best For |
|---|---|---|---|---|
| Cached data | Stale (minutes/hours); include freshness timestamp | Low | Low | Read-heavy data: prices, catalogs |
| Partial response | Fresh (core only) | Medium | Medium | Non-critical enhancements: reviews, recommendations |
| Queue for later | Delayed | High | Low | Write operations: emails, payments |
| Backup service | Fresh | Very High | Minimal | Business-critical APIs: auth, payments |
"The point is not to fail silently or return incorrect data. We're making an explicit decision to continue operation in a degraded mode... and we're returning metadata that lets the calling code inform the user appropriately." - Juan Carlos González Cabrero, Senior Software Engineer
Design degraded states for users and operators
A fallback can’t stop at the code level. It also needs to tell users, in plain English, what still works.
Raw error output - stack traces, HTTP status codes, cryptic messages - doesn’t help people get their job done. If a dependency is unhealthy, show a clear status message, make it obvious that the system is in a degraded state, and explain what the user can and can’t do right now.
For example, a banner that says "Pricing data is temporarily unavailable - showing last updated values from 14 minutes ago" is much more useful than a 503. A read-only mode label when a write API is down tells operators what they can still do without trial and error.
A good degraded state keeps the workflow alive instead of burying the problem behind a generic error. These levels give you a simple way to name and design those states:
| Level | What Works | User/Operator Experience |
|---|---|---|
| Partial | Core features; enhancements hidden | Minor loss of non-essential data |
| Minimal | Read operations; writes queued | "Can browse, can't submit changes" |
| Cached | Stale data only | "Data as of X minutes ago" banner |
| Maintenance | Nothing | Friendly "Service Unavailable" message |
Make the degraded state easy to scan so operators can see the scope of the issue and the next step right away.
Monitor, test, and tune resilience over time
Resilience needs attention over time. Traffic shifts. Dependencies change. What worked six months ago can start cracking under new load.
Once your fallbacks are live, check whether they behave the way you planned under actual traffic.
Track latency, errors, retries, and circuit breaker events
At a bare minimum, track latency percentiles like p95 and p99, error rates by class (4xx vs. 5xx), retry counts, and circuit breaker state changes for each dependency. Retry rate deserves extra attention. If retries go above 5% of total requests to any one provider, that usually points to system-wide degradation, not a small blip.
These signals each tell you something different:
| Signal | Examples | What it Detects |
|---|---|---|
| Metrics | Latency (p99), error rate, retry count | High-level instability, rate-limiting (429s), and capacity bottlenecks |
| Logs | Structured logs with correlation IDs | Specific record failures and audit trails |
| Traces | OpenTelemetry, W3C Trace Context | Where latency builds up or which hop in a call chain is failing |
| Resilience events | Circuit breaker state, fallback activation | Degraded states where the system still works but not in a normal state |
Pass correlation IDs across every hop. W3C Trace Context is a solid fit here. When an incident lands, you want to follow one failed request from start to finish in minutes, not burn hours piecing it together. And if a circuit breaker opens with no alert, you can end up with hidden degradation: the system is broken, but nobody sees it yet.
"Resilience without observability is guessing." - Amr Samir
Those signals should guide your next moves: what to inject, what to stress, and what to tune.
Validate behavior with failure injection and load testing
Test the failure modes you already planned for. Run failure injection in staging at least quarterly. Block secondary APIs. Inject 5xx responses. Add artificial latency. Drop packets. Simulate a full dependency outage. The point is simple: prove the system degrades in a controlled way.
Then pair that with load testing using tools like k6 or Locust. This helps you find where latency starts climbing and which dependencies fold first under pressure. It also gives you a clean way to check your retry budgets. A five-deep call stack where each layer retries three times can blow up one request into 243 downstream requests. That’s the kind of math load testing exposes before production does.
Review timeout and retry limits every quarter. If queue depth stays above zero on a steady basis, that usually means your concurrency limits are too tight for current traffic. Fix it before it turns into rejected requests.
Conclusion: Build for controlled degradation, not perfect dependencies
A distributed system with 30 dependencies, each at 99.99% uptime, still ends up with only 99.7% composite uptime - about 2 hours of downtime per month - if those dependency edges are not defended on their own. Resilient integrations protect users from total failure by degrading in a predictable way. Build for controlled degradation, then keep tuning it as dependencies change.
"A resilient API is not an API that never fails. That does not exist. A resilient API is one that knows how to fail in a controlled way." - Amr Samir
FAQs
How do I choose the right timeout values?
Avoid default infinite timeouts. They can trigger cascading failures fast.
A good starting point is the downstream service’s p99.9 latency, plus a small buffer for network variance. Say a service usually responds in 200 milliseconds. In that case, a timeout of 500 milliseconds to 1 second is a sensible place to start.
It also helps to set a clear timeout hierarchy so one slow call doesn’t eat up the whole request:
- Connection timeout: 1 to 3 seconds
- Request operation timeout: 5 to 30 seconds
- Overall user-facing request budget: 30 to 60 seconds
That structure keeps each layer on a leash and makes slowdowns easier to contain.
When should I use async instead of sync API calls?
Use asynchronous processing when the user doesn’t need a task to finish on the spot. A simple pattern is to confirm the request right away, then do the work in the background.
This helps keep your app responsive and cuts down on time spent waiting for slow dependencies. It works especially well for webhook processing and other non-critical operations that may need retries or dead-letter queues.
How do I prevent duplicate writes during retries?
Use an idempotency key so the same logical operation runs only once, even if the request gets retried. The client sends the same key each time, and the server returns the original stored response instead of doing the write again.
For this to work well, a few things matter:
- Use a unique database index on the idempotency key
- Store the result in the same atomic transaction as the business operation
- Check that the payload matches the original request before returning the stored response
That setup helps you avoid duplicate writes when networks get flaky or clients retry after a timeout.